Image segmentation. We would not manually cut desired parts of the image since that would require too much work. Instead, we would use the concept of image segmentation to separate different desired parts of the image such as colors. The process requires the binarization of the image through a threshold that would be set for the image.
For a certain region of interest, we would separate this region and the parts of the image which contains the same properties and isolate them. The binarization process converts the colored image into an image composed of black and white. Upon isolation, it is upon us on what to represent the isolated parts of the image. To give us a good look, we observe an example.
Grayscale Image Segmentation

We considered a check in grayscale. Suppose we desire to isolate the hand writings and computer generated scripts in the check, we refer to the Scilab code given from the manual.
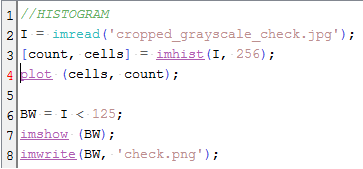 The code starts by investigating on the histogram of the grayscale image. The histogram would tell us the details about the pixel values of the grayscale image. The histogram can be seen below.
The code starts by investigating on the histogram of the grayscale image. The histogram would tell us the details about the pixel values of the grayscale image. The histogram can be seen below.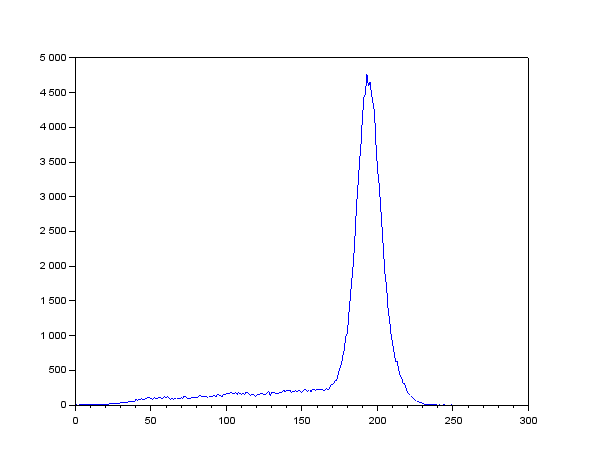 The peak location in the histogram corresponds to the background of the check. We can infer that they cover a lot more space than the text in the check. By choosing a threshold of 125 as shown in Line 6 of the code, we could separate the text completely from the background. The result can be seen as follows.
The peak location in the histogram corresponds to the background of the check. We can infer that they cover a lot more space than the text in the check. By choosing a threshold of 125 as shown in Line 6 of the code, we could separate the text completely from the background. The result can be seen as follows.

The result clearly shows that we have segmented the text from the check. We can also try different thresholds to observe if we could improve more on our segmentation. This is the case for grayscale images but as can be seen in the image below, it does not always work this way.

Because of this tragedy, we consider color segmentation for our images. Color is one good parameter to consider to separate regions of interest from the image. It has long been used to segment images of skin regions in faces, and
hand recognition, land cover in remote sensing, and cells in microscopy [1].
For this reason, we should consider a representation of the color space. We also need to consider the shading variations in different images where shadows darkens some colors but knowing the image, we could observe the same color for two regions. To disregard this minor problem, we would consider a color space that can separate brightness and chromaticity information [1]. This color space is the normalized chromaticity coordinates or NCC.
We first normalize the RGB coordinates by this way,

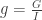
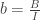
where 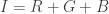
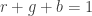
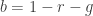
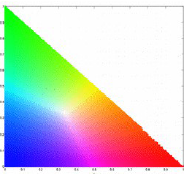
We clearly can see the dependence of the blue coordinate with the other two. When both r and g are zero, b =1 which is still consistent with the unity of all coordinate channels. Two methods of image segmentation are presented for this activity. For both activity we would try to segment the following images.

Civil War comic strip obtained from http://www.vox.com/2014/10/14/6973309/robert-downey-jr-captain-america-3-movie

Obtained from http://polygonblog.com/3d-birthday-balloons-in-3ds-max/
The patches considered for each images for the whole activity is given below.

 The top set of 2 patches were used for the Civil War (CW) image while the bottom set of 4 patches were used for the Balloon (B) image.
The top set of 2 patches were used for the Civil War (CW) image while the bottom set of 4 patches were used for the Balloon (B) image.
Parametric Segmentation
In parametric segmentation, we consider a color distribution of interest to determine the probability of a pixel belonging to the region of interest. We first crop a region of interest and observe the histogram of the region of interest. Since we are considering the NCC, we would find the probability that a pixel belongs to the region of interest (ROI) by finding the probability that the pixel belonging to the color of the ROI. We consider both probabilities for the red and green coordinates of our NCC. The probability that the pixel belongs to the ROI is given by the equation,
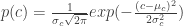
where c is the color red or green. 

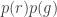
The simple code used for the parametric segmentation of the two images is shown below.
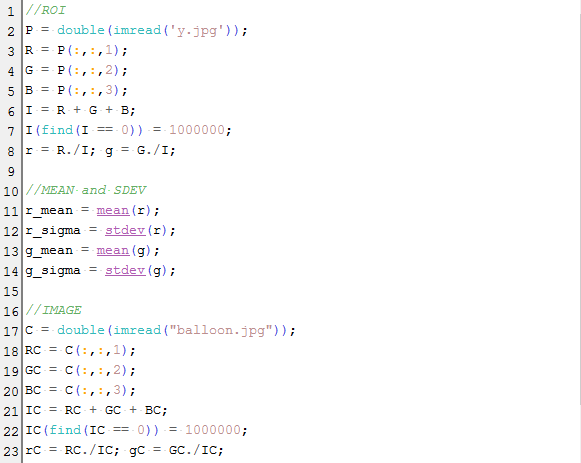

We first converted the RGB coordinates of the ROI into the NCC in Lines 1-8. The mean and standard deviations of these coordinates were calculated in Lines 10-14. The RGB coordinates are also converted into the NCC in Lines 16-23. The joint probability distribution is obtained in Lines 25-30. We placed different thresholds to observe image segmentation. Upon applying the code, we look into results of parametric segmentation in 2 images considered.

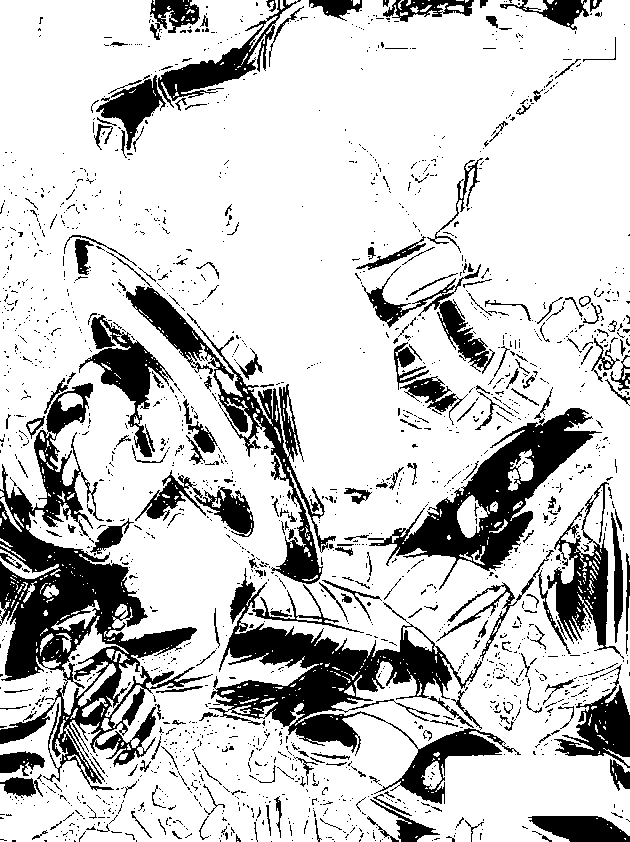
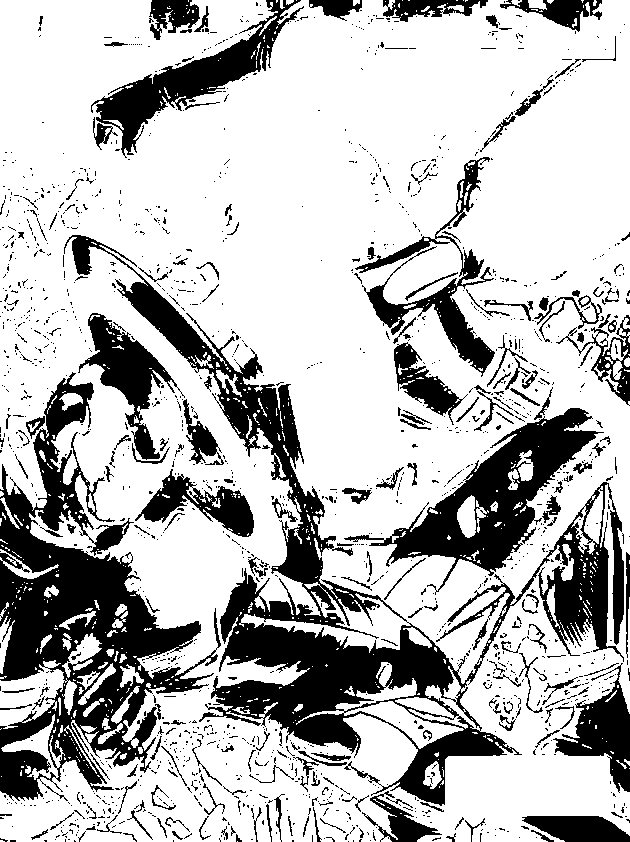
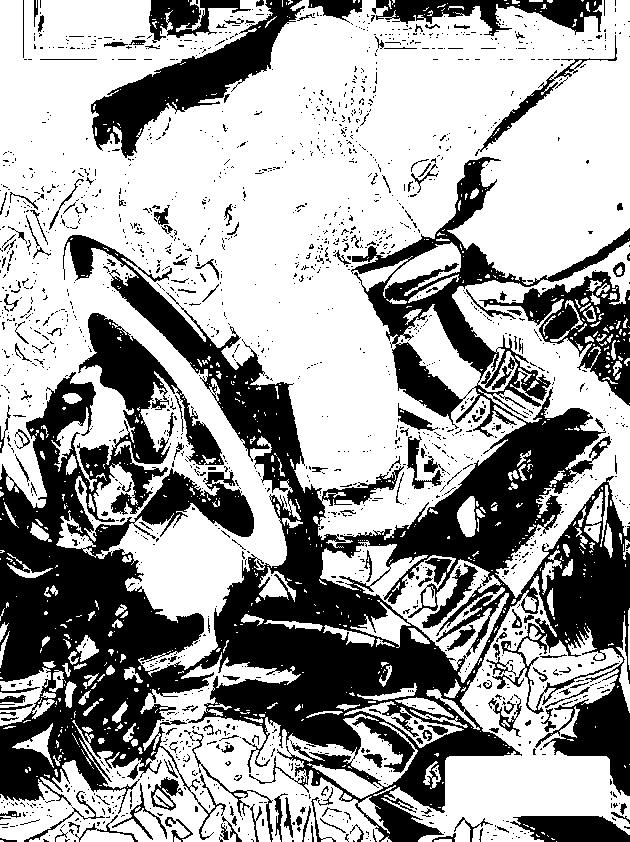
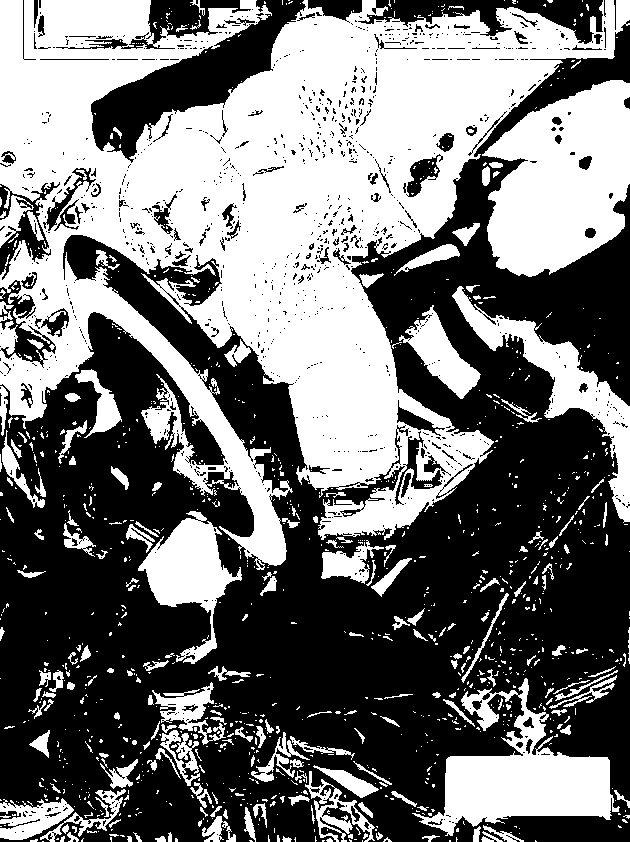
The CW image was segmented using the blue patch as ROI. Segmentation with different thresholds ranging from 0.75 – 0.95 with increments of 5 were produced. As we can observe the higher the threshold, the better segmentation we can obtain. The last image proves the power of segmentation, clearly isolating the blue uniform and some parts of the shield of Captain America. It was an awesome piece of art for me since through simple calculations of probability distributions, we can segment the some regions of an image. For the red patch, we obtain the following results,




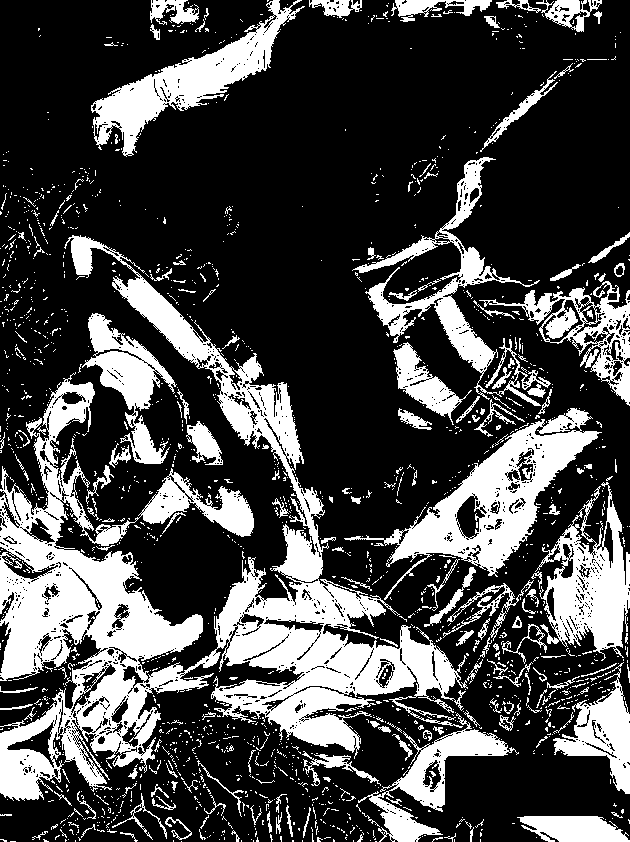
The CW image was segmented using the red patch as ROI. Segmentation with different thresholds ranging from 0.75 – 0.95 with increments of 5 were produced. The same kind of results were obtained, noting that the last image clearly isolates the red steel of Iron Man.

For a fun kind of segmentation, I had fun in the next image considered. Some results are as follows.


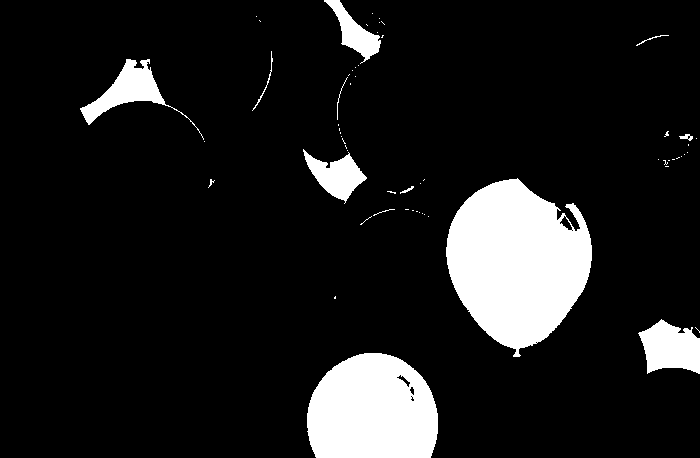
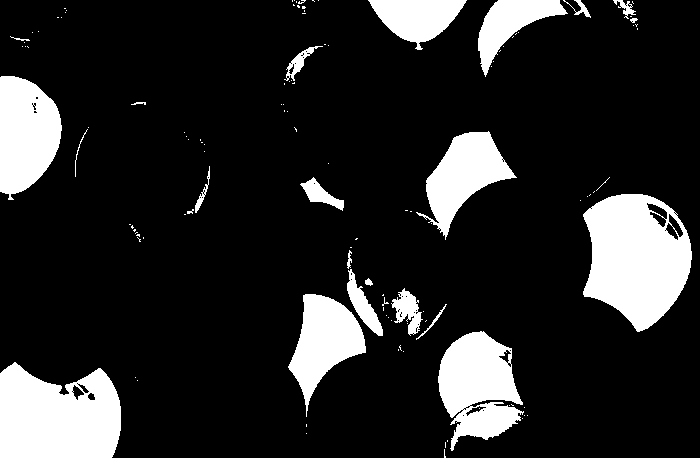



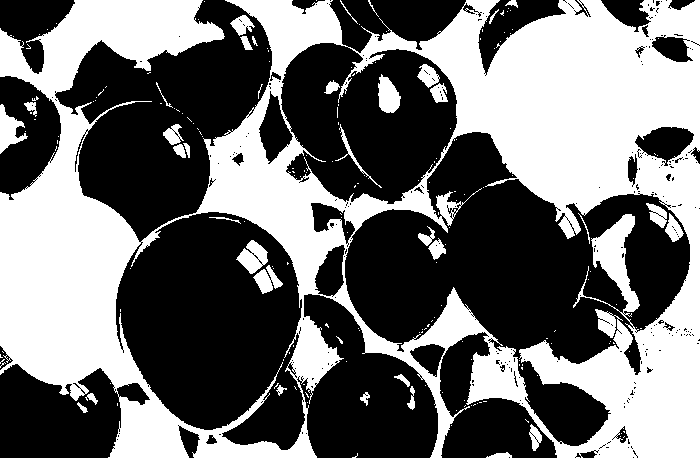
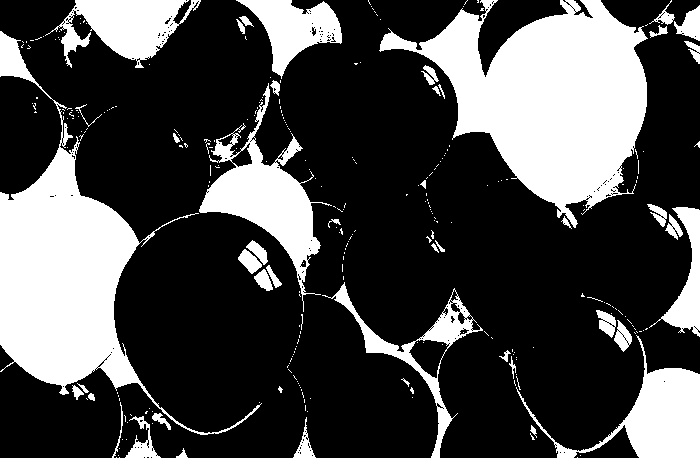
From left to right for all sets of results, the thresholds considered are 0.90 and 0.95 respectively. The first two sets used a patch of blue. There was a big difference in the two results. Referring to the original image, we can clearly choose that the right result is the one with the threshold of 0.95. The other result considered the purple balloons as part of the region of interest which we can forgive since blue and violet are colors which are close to each other.
The next two sets used a green patch as ROI. Both results are favorable but the image with a threshold of 0.90 considered the blue green balloons to be part of the ROI. But thresholds were used to eliminate some of these mistakes.
The 3rd set used a red patch as ROI. With threshold of 0.9, the returned image considered some orange balloons as part of the ROI. But then with the threshold raised to 0.95, only red balloons were considered. This set was the best set for me since I was amazed that the algorithm used denied the entry of the window-like shadow and some reflection in the right most red balloon.
The 4th and last set used a patch of yellow for ROI. For both results, orange balloons were considered. Somehow even with a high threshold, some of these errors occurs. I believe that changing and being careful of choosing the ROI could avoid this kind of mistakes.
Overall, the method of parametric segmentation proves to be a good and accurate choice for image segmentation. Though we could note that for larger sizes of image, a larger processing time would be expected. These are some important factors we need to consider for choosing our method of image segmentation in the future.
Non-parametric Segmentation
In parametric segmentation, we basically fit an analytic function to the histogram to create a function in checking if the pixel of an image belongs to the ROI. But the method’s accuracy depends solely on the goodness of the fit of the probability distribution function considered.
In the non-parametric segmentation, we use the histogram itself to admit the pixel as member of the ROI. A technique called histogram backprojection is necessary to perform non-parametric segmentation. Histogram backprojection tells us that basing on the color histogram, every pixel location is given a value equal to the histogram value in chromaticity space [1].
We first convert the r and g chromaticity coordinates into integer values and binning the image values in a matrix. The technique of histogram backprojection is shown in snippets of code below.
 Lines 1-6 converts the RGB components into chromaticity coordinates. The 2D histogram was made in Lines 8-18. The r and g values were first converted into integers and then binned these image values in a matrix.
Lines 1-6 converts the RGB components into chromaticity coordinates. The 2D histogram was made in Lines 8-18. The r and g values were first converted into integers and then binned these image values in a matrix.
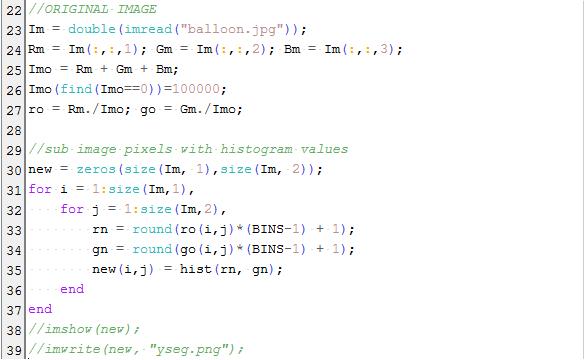
The RGB values of the original image was converted to chromaticity coordinates in Lines 22-27. The process of histogram backprojection can be seen in Lines 29-37. In Line 35 the pixel location is given a value equal to its histogram value in chromaticity space. To better understand this concept, let’s discuss the results.
For the CW image, we obtain the following histogram for our patches. The first histogram is for the blue patch and the bottom histogram pertains to the red patch. The NCC image is shown next to the histogram to properly locate the locations of the color of the patches considered.

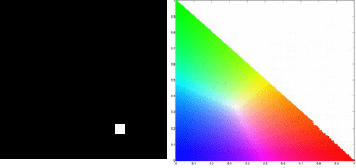
We can clearly confirm the correctness of the histogram obtained for both patches. These histogram serves as the basis for our new pixel values of the original CW images. Performing histogram backprojection to the CW image, we obtain these results.


The middle image is the result of the non-parametric segmentation of the original image (left most image) for the blue patch. The last image is the result for the red patch. For the blue patch, we can clearly observe the isolation of the blue color of the uniform of Captain America. For the red patch there are some parts that were not segmented. These results proved that the patch used for segmentation matters so much. I feel that if I replace the patch with a better patch, I would obtain much better results.

For the balloon image, I obtained the following histograms for the following patches: blue, green, red and yellow respectively.
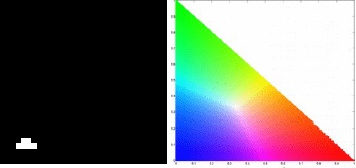
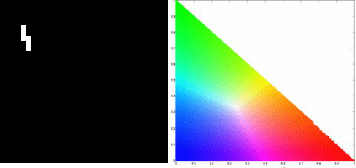
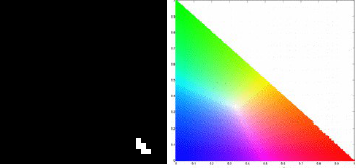
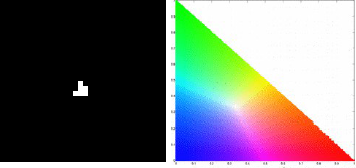
We obtain correct histograms for the patches. The results of non-parametric segmentation of the balloon image for each patch is shown below.
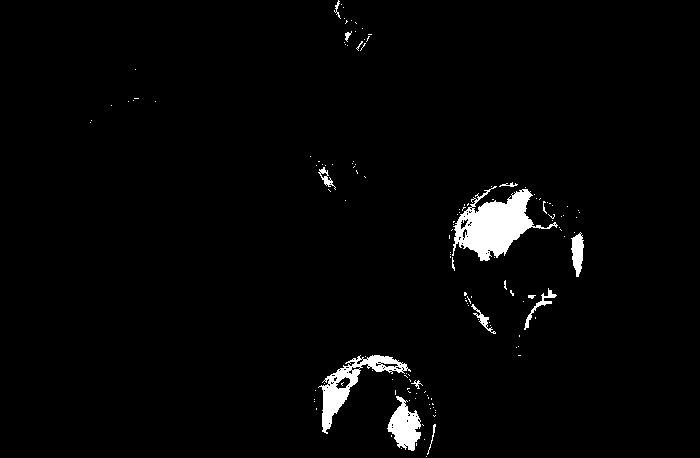
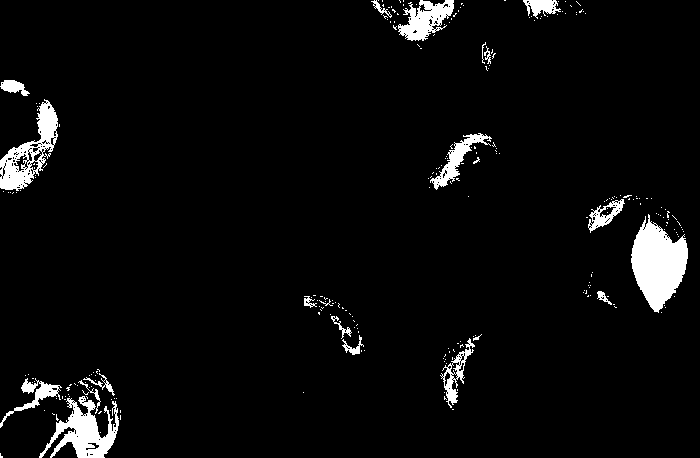


Again I believe that improving the patches considered for segmentation, we can have better results. The patches might be uneven or worse, a shade darker or lighter than most of the colors of the images.
Non-parametric segmentation is a more flexible method compared to the parametric method. Because we consider histograms, we could define ROI’s of multiple colors and still effectively segment the image. The parametric segmentation has the limitation of having an ROI of only a single color. Non-parametric segmentation also has a faster processing time since it involves no computation. The 2D histogram contains more reliable information for the pixel values we aim to segment.
After finishing the activity, I felt more skillful in image processing. A new skill such as what we gain in this activity is overwhelming. I just know that somewhere and sometime I would be able to use my new gained skill. I had lots of fun in this activity. I was amazed by my results. I am in awe of how simple the process could be to segment the images with the desired ROI. Soon I’ll add some more results which I would be able to do on some leisure times. I already have ideas on mind and I hope it would bear fruit.
Overall, I give myself 10 points for this activity because I believe I was able to do what is asked. The results I obtained are great and clearly what were asked for. Since I was not able to go beyond what is asked for, I do not deserve some extra points. If anything else, I gained lots of new skills due to these strings of activities we have for AP 186. Thank you Maam for being patient with us through these activities.
PS. I would like to thank Ron Aves, Gio Jubilo and Ralph Aguinaldo for giving me some insights on some parts of the activity.

Reference:
- A7 – Image Segmentation, Applied Physics 186 Activity 7 Manual, Dr. Maricor Soriano











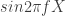 where f is the frequency. Its FT was obtained and the FT modulus was displayed. With a frequency of 4, the sinusoid and its FT is shown below.
where f is the frequency. Its FT was obtained and the FT modulus was displayed. With a frequency of 4, the sinusoid and its FT is shown below.




















 , we obtained the following results. We can observe the spacing of two dots increases as the frequency of the original sinusoid is increased. We can also observe another set of 2 dots in the middle which can be attributed to the very low frequency added. So for an interferogram setup where a non-constant bias is added, we still can determine the frequency of the interferogram by simulation and the use of Fourier transform.
, we obtained the following results. We can observe the spacing of two dots increases as the frequency of the original sinusoid is increased. We can also observe another set of 2 dots in the middle which can be attributed to the very low frequency added. So for an interferogram setup where a non-constant bias is added, we still can determine the frequency of the interferogram by simulation and the use of Fourier transform.









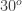 , the new sinusoid form is in the form
, the new sinusoid form is in the form  . The resulting images and their FTs for different frequencies is shown below.
. The resulting images and their FTs for different frequencies is shown below.







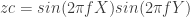 in different axes and their resulting FTs are shown below.
in different axes and their resulting FTs are shown below.






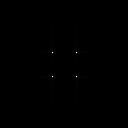












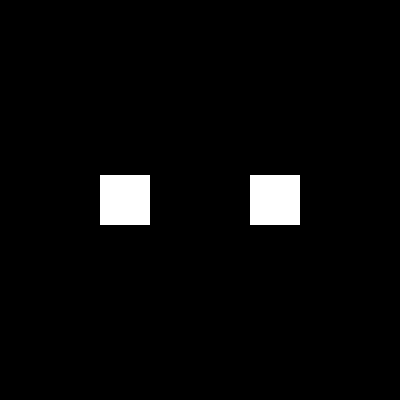



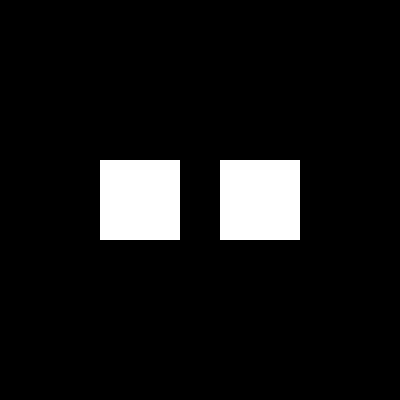


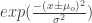 of varying
of varying